How We Shrink CI Time by Over 80% Without Scaling Up
Pramesti Hatta K.
- 6 minutes read - 1260 wordsIn this blog post, I’ll share our recent improvement where we reduced our Continuous Integration time by over 80% by implementing a Selective Testing Strategy.
Introduction
At SawitPRO, we maintain a large monolithic backend codebase written in Go that powers the services our customers rely on daily. As our customer base has grown and their needs have evolved, we’ve accelerated our feature delivery to a weekly cadence. To ensure our customers continue receiving stable, high-quality services while we innovate rapidly, we’ve established a strong culture of comprehensive unit testing throughout our development team.
This rigorous approach to testing has been a foundation of our development process to ensure our customers receive stable, reliable software. By enforcing high unit test coverage across all packages, we protect our customers from experiencing unexpected bugs or service disruptions. This has proven invaluable in maintaining customer trust, especially in our monolithic architecture where code changes can have far-reaching effects on the customer experience.
To support our rapid development cycle, we also follow a trunk-based development approach. This means that all developers work on short-lived branches that are merged into the main branch frequently, often several times a day. This strategy keeps integration pain low but makes fast and reliable CI pipelines absolutely critical, as every commit to the trunk must be thoroughly validated before merging.
However, this discipline also comes with significant trade-offs. As the codebase and the corresponding test suite have grown, the time it takes to run our CI/CD pipelines has increased as well. Every pull request now triggers tests across hundreds of packages, and even minor changes can result in long waiting times before a merge can proceed. Delivering software fast is very important for us as we want to shorten the customer feedback loop as quickly as possible.
Before the optimization, we were facing a significant bottleneck in our pipeline, specifically in the pull request validation workflow. One major reason is our unit tests, which are executed synchronously, one package at a time, across the entire backend repository. This can cause the pipeline to take over 25 minutes to complete—an unproductive and frustrating delay.
This delay affected our entire release process. The longer it took to validate pull requests, the slower we were at getting code into staging environment, which in turn delays QA testing and ultimately, production deployments.
To move faster and smarter, we needed to optimize our CI workflow to make it both effective and efficient. There’s a clear opportunity here to improve speed and unlock a smoother development cycle for everyone involved.
We strongly believe that true performance improvements should be achieved by optimizing the codebase and workflow logic, rather than simply throwing more hardware at the problem.
Problem Statements
Let’s examine the two key challenges we’re facing with our current CI pipeline setup:
- Long CI Pipeline Duration: Our CI pipeline takes 25+ minutes even for minor changes, creating a bottleneck in our workflow. This waiting period disrupts developer flow and delays the entire release process.
- Reduced Developer Productivity: Long waiting times force developers to context-switch while waiting for CI results, decreasing focus and ultimately slowing feature delivery to customers.
Selective Testing Strategy
The solution we implemented is simply a Selective Testing Strategy.
The idea is:
- When a developer makes a change, we first identify the specific packages that have been modified and add them to the “packages to be tested” list.
- Tests will then be executed only for those changed packages, while the rest, which have not been affected, will be safely skipped.
However, we must also consider package dependencies. In many cases, a package may serve as a dependency for other packages. If a dependency changes, it can potentially impact the behavior of all packages that rely on it. Therefore, we must not only test the directly changed packages but also any packages that depend on them. This ensures we catch any regressions or side effects early.
Also, to maintain efficiency and avoid redundant work, we need to track which packages have already been added to the “packages to be tested” list.
- If a package is encountered multiple times in the dependency chain, we check if it has already been added to the list.
- If it has, we skip it.
- If it has not, we add it to the list to ensure its integrity.
By implementing this selective testing strategy, we will:
- Drastically reduce pipeline time, improving developer experience and productivity.
- Save costs by reducing unnecessary GitHub Actions minutes.
In short, this change makes our CI pipeline smarter, faster, and more cost-effective, helping us ship better software more efficiently.
Flow
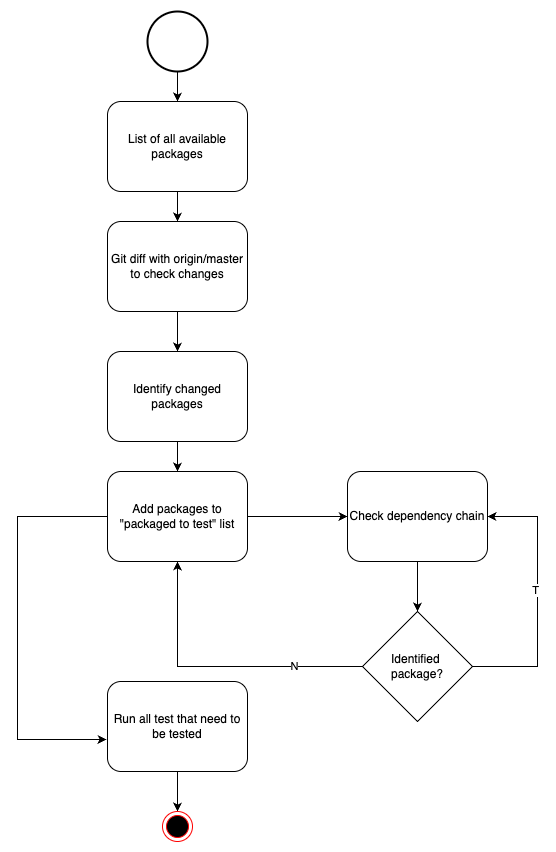
Implementation
Fortunately, the Go ecosystem provides powerful built-in tools that make this optimization both feasible and straightforward. The go command-line tool, along with standard Git commands, enables us to build a selective test workflow.
To implement this idea, we rely on the following:
go list: to enumerate all packages in the codebase and inspect their dependencies.git diff: to identify which files and packages have changed compared to the main (or master) branch.go test: to execute unit tests selectively for only the affected packages.
We’ve encapsulated the logic into a simple bash script that performs four main steps:
- List all packages in the codebase
- Identify changed packages
- Determine and traverse dependency chain
- Run tests selectively
Result
Before:

After:

It’s an 82.6% improvement or 5.7x faster. This significant improvement will shorten our customer feedback loop and further reduce the cost of our CI pipeline.
Other Solution
Another solution that we can try is to use GitHub Running variations of jobs in a workflow. With this approach, we can test the entire package and split it into multiple jobs, so each test will spawn one runner and the processes will run parallel to all the packages.
I did a small experiment with this solution and it takes around 2-3 minutes to finish each test, but the problem is that it increases our minute usage. If we have 100 packages and each package consumes 2 minutes, then in total we’ll consume 200 minutes for one pull request validation—making our unit tests faster but less efficient.
Moving Forward
Another optimization we’re planning is to enable parallel execution of unit tests, which Go supports natively via its testing framework. By leveraging parallelism, we can significantly reduce the total execution time, especially when dealing with a large number of test files or packages. However, we’re currently facing a blocker with some of our older unit tests. These tests make use of shared mocks, which introduce race conditions or conflicts when multiple tests run in parallel.
Once we successfully refactor our legacy unit tests and fully enable parallel test execution, it’s natural to ask:
“Do we still need selective testing?”
Parallelism will indeed speed things up by running multiple tests or packages simultaneously. However, there are some key considerations that suggest selective testing can still be highly valuable, even in a parallelized environment.
We don’t have a definitive answer yet, but our hypothesis is: Selective + Parallel testing will give us the fastest, most cost-effective, and scalable solution.
Do we still run full unit tests for sanity checks? Yes, for every deployment to production, we still run the entire unit test suite.
There are also multiple sophisticated build systems like Bazel or Buck/Buck2 that address this issue as one of their features. We plan to consider these tools once our requirements become more complex.
If you’ve been facing similar CI/CD challenges in your tech stack, I’d love to hear your thoughts and experiences in the comments section of our SawitPRO Talent Community.